1、问题分析
立体匹配问题,即根据双目摄像头拍摄到的参考图像和目标图像,确定参考图像上每个点在目标图像上对应位置的一个过程。一般展示效果通过输出视差灰度图或伪彩色图像表示实际物体远近程度。直观上人眼可以直接评判立体匹配效果的好坏,客观上可以根据数据库提供的真实视差图计算匹配错误率,错误率越低说明模型的准确度越高。
近年来,随着深度学习的发展,卷积神经网络在越来越多的计算机视觉任务上大展身手,取得了惊人的进步,大幅提高了各项视觉任务挑战赛的最高水平。与传统方法不同,深度学习依赖于深层神经网络对问题进行建模,相对于浅层结构,深层结构能学习到更为复杂的非线性关系。同时,卷积神经网路直接以图像为输入,减少了认为设计特征的工作量。与此同时,大规模的训练样本和高性能训练设备也显得尤为重要。
研究的该篇论文采用KITTI2012数据集训练卷积神经网络,用于训练的图片只有194对,其中还有一部分需要用于验证模型训练程度和参数,若直接使用原始图像对作为训练输入,样本数量过少,无法得到较好的效果。因此考虑从原始图像上截取图像块作为网络训练样本,因此接下来所述网络本质上属于局部匹配方法。
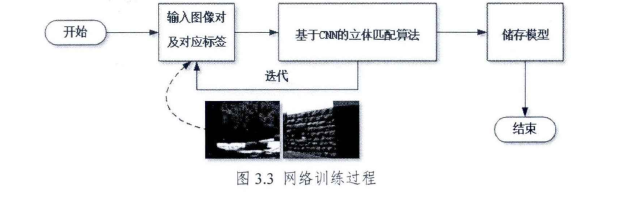
该论文中考虑将问题限定为一个有监督的机器学习问题,其训练过程如图3.3所示,将数据分为训练集和测试集,训练集由训练图片对和真实视差获得,通过不断地迭代过程使得本文提出的模型收敛,并存储整个模型的参数,方便对后续的图片进行测试和验证。
论文中所使用的数据集、网络结构及训练方法将在后文详细介绍。
2、训练数据
该论文采用的每条训练数据由两个图片块组成,记做<Ps×sR ,Ps×sT>,图像块的大小s与网络中卷积层的数量n成线性关系,具体为:
s = 2xn+1 (3.14)
这样设定的目的是即使改变网络结构,也可以轻松地自动生成对应的图像块。Ps×sR (p)表示从参考图像IR 截取的大小为s x s,中心为p的图像块,Ps×sT (q)表示从目标图像IT截取的大小为sxs,中心为q的图像块。
由于对于训练数据,p处的真实视差d已知,我们可以根据真实视差分别生成一组正样本和负样本。令q = (xp -d + Oneg,yp),其中Oneg 是负样本补偿参数,它从 中随机选取,则<Ps×sR (p),Ps×sT(q) >是一个负样本。类似地,令q = (xp -d + Opos,yp),其中Opos是正样本补偿参数,它从
中随机选取,则<Ps×sR (p),Ps×sT(q) >是一个负样本。类似地,令q = (xp -d + Opos,yp),其中Opos是正样本补偿参数,它从![]() 中随机选取,则<Ps×sR (p),Ps×sT(q) >是一个正样本。同时,记正样本的输出标注为1,负样本的输出标注为0.根据以上分析,可以认为该论文所提出的卷积神经网络在立体匹配任务中实现了计算匹配代价的功能。
中随机选取,则<Ps×sR (p),Ps×sT(q) >是一个正样本。同时,记正样本的输出标注为1,负样本的输出标注为0.根据以上分析,可以认为该论文所提出的卷积神经网络在立体匹配任务中实现了计算匹配代价的功能。
值得注意的是,由于对网络输出结果还需要进行后续步骤的精炼,网络的输出结果应该与经典的局部匹配方法输出具有相同的形式,即正样本输出结果应小于负样本输出结果。因此在网络训练完成后进行测试时,网络输出结果要乘以-1使其符合匹配代价的形式。
本文在训练网络时,使用KITTI2012数据集进行网络的训练。KITTI2012数据集共含有194组训练图像对及其真实视差。为了避免过拟合及参数调优,本文使用1/4的有效点作为验证集。
为了使网络具有更好的泛化能力,本文使用了缩放、调整对比对、调整亮度等手段人为地对图像块进行了预处理。
上面提到的Nlo,Nhi,Phi 是独立于网络结构的超参数,一般通过结合验证集合经验法确定。
3、网络结构
本文使用的网络结构如图3.4所示。网络含有4个隐含层,且为全卷积结构,因此在测试阶段可以很方便地使用各种尺寸的输入图像进行测试。4个卷积层对应的网络输入为1x9x9的图像块,第一维为1表示灰度图像。第一层卷积层(C1)的卷积核尺寸为64x1x3x3,第二到四个卷积层(C2,C3,C4)均由64x1x3x3的卷积核构成。第四个卷积层(C4)的输出为左右两个64x1的特征列向量,第五层网络输出层为第四层输出向量内积的累加和。除最后一个卷积层(C4)外,每个卷积层输出结果经过一个ReLU层,最近一些研究证明,ReLU层在训练CNN时能够提高收敛速度。
由于网络第一层64x1x3x3的卷积核,因此本网络输入只能使用灰度图像,但只要简单地将第一层卷积核改为64x3x3x3的卷积核,本网络即可接受RGB彩色图像作为输入。
由于该网络结构输出可以作为匹配代价用户后续步骤的处理,故将此卷积神经网络命名为代价卷积神经网络(Cost Convolutional Neural Network,简称CCNN).方便后文的理解。

4、网路的训练过程
该论文网络训练流程图如图3.5所示。
首先将KITTI2012数据集194组训练图片随机打乱,选取其中160组图像作为训练集,用于训练网络参数,剩余34组作为验证数据集,用于验证模型参数。
KITTI2012数据集提供的真实视差图为稀疏视差图,即其中有部分点的真实视差未知,另外由于摄像头视野限制,左图中左侧部分区域无法匹配右图中对应位置,即无法通过计算获得其视差,因此需要对有效训练点进行筛选。给定参考图像中一点p和真实视差d,筛选条件如下:1)d为0的点;2)p在目标图像中对应点pd的横坐标小于0.
通常训练一个深度神经网络需要大规模的数据,而当训练数据不足时,常用的策略是使用ImageNet数据集对网络参数进行预训练(Pre-train),使网络参数能有一个较好的初始值,加快收敛速度。故目前大部分使用深度学习完成视觉任务的项目,常常会使用ImageNet数据集对网络进行预训练,再用当前任务的数据集对模型参数进行微调(Finetune)。
如前2中所述,使用该论文准备数据的方法可以获得近1500万个有效点,每个有效点可以生成一组正样本和一组负样本,共约3000万组样本,已经足够用于一般的学习任务,故不需要进行预训练步骤。 卷积层的卷积核参数采用均值为0,方差为0.01的高斯分布随机初始化。该论文使用SGD算法更新权重,mini-batch为128个样本,momentum为0.9,前12次迭代时学习率为0.00002,共20次迭代。

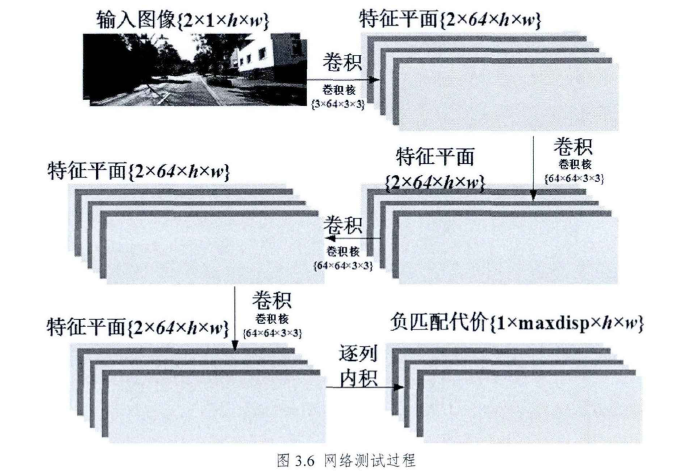
5、网络测试过程
网络测试流程与训练流程略有不同。如前所述,训练时网络输入为2组9x9的灰度图像块,卷积层的填充宽度为0,故经过多个卷积层后输出1个实数,表示两个图像块的匹配程度。由于网络是全卷积结构,所以卷积核尺寸都是3x3,根据下图所示(3.4)公式,通过将填充宽度设置为1,可以使得网络的输入输出的尺寸相同。即输入参考图像和目标图像,卷积层C4输出尺寸与输入相同,再将向量内积改为第二维逐像素列向量的内积,可获得负匹配代价-C(p,d)。

一般来说,局部匹配算法包含代价计算、代价聚合、视差计算、后处理四个步骤,为了简化实验步骤,该章实验并未进行代价聚合,直接用网络输出的视差空间图进行视差计算并输出结果。
另外,若以左图为参考图像,左图上一点p在视差d的匹配代价,与以右图为参考图像,右图上点pd在视差d的匹配代价相同,因此CCNN可以分别获得以左右图作为参考图像的匹配代价,可用于后处理。